VFP
performance in LAN environment
Author: Josip
Zohil,
Visual FoxPro is one
the fastest performing desktop and LAN-based database management system
available today. But opening large tables creates a great deal of network
traffic. This can be a substantial delay, sometimes beyond an acceptable length
of time. In this article I present the results of the VFP speed measurement in
the process of acquiring database data with different VFP9 methods. The store
procedures, duplicated records and unique indexes enriched by the programmers’ knowledge
of the database organization can speed up the data query. With the stored
procedure we can fetches the result set of 100 records from the server about
100% faster than with the full optimized SQL command. Changing the table’s
normalization and using appropriate indexes, we can improve the retrieval time
for 275%.
1 The problem
Let us start with an
example. The fields of the ordnorm
table with 50.000 records of the company with multiple warehouses are:
-
OrderID - the order identification number, indexed
field;
-
WareID
– the warehouse identification number, indexed field;
-
DocType
– the type of the document, indexed field;
-
OrderDate
- the order date,
-
IncNo
– auto increment value, primary key.
The first seven fields
(among 40 fields) of the orddet
table with 750.000 records (350 MB) are:
-
OrderID
- the order identification number,
indexed field;
-
WareID
– the warehouse identification number, indexed field;
-
DocType
– the type of the document, indexed field;
-
ShipDate
– the date of shiping the article (The orders items may be shiped at different
date), indexed field;
-
IncNo
– auto increment value, primary key.
-
ArtId
– the article warehouse identification
number, indexed field;
The structural orddet.cdx
file is of 66 MB.
For a DocType with ID
4 and warehouse with ID 14 we want to
download from the server the data in the fields WareId, DocType, OrderID and ShipDate
group by this fields. In the command window of the workstation (250 MB RAM) we
wrote the SQL query:
SELECT ordnorm.wareid,ordnorm.doctype,ordnorm,.orderid,orddet.shipdate FROM ordnorm LEFT OUTER JOIN orddet ON orddnorm.wareid+ordnorm.doctype+STR(ordnorm.orderid,6)== orddet.wareid+orddet.doctype+STR(orddet.orderid,6) WHERE ordnorm.wareid+ordnorm.doctype= "14 4" AND ordnorm.orderid>170000 INTO CURSOR (lc1) GROUP BY ordnorm.wareid,ordnorm.doctype,ordnorm.orderid,orddet.shipdate (Q1)
In the 100Mbit LAN the
data (6,000 records) arrived at the workstation after 15.37 seconds. At certain conditions (for example on the second
retrieve) VFP is extremely fast (1.2 seconds), so it is much better to
thoroughly look into the factors that influence its performances. The time
difference can be explained by the Robert C. Bradley description of the VFP processes:
'But VFP gets its phenomenal performance by taking advantage of the LAN
environment, pre-fetching columns of information, caching table headers and
index contents locally' [1]. But the first time, after the opening of the table
the fetch of the records from the server is far from being extremely fast, it
is a very slow (15 seconds). How to improve this poor performance? Which
factors influence it?
In developing new
application it is relatively difficult to test its performance on large dbf
files. So the problems rise with the maturation of the application. In its
mature stage we normally look for application improvements we can realize with
small modification: store procedure and unique indexes are between them.
2 The solutions
There are many hypothetical
solutions we can try inside of VFP. We shall study the retrieval time
dependences from:
-
the
table normalization;
-
the
size of the index structural file,
-
the
type of the index (unique),
-
the
retrieval method (SQL select, stored procedure),
-
the
size of the result set and the method used.
Let us test some of
this solutions on the workstation with 512 MB RAM that is operating in the 100
Mbit LAN with a server and a workstation (On the workstation with 256 MB RAM
the results change significantly, but don’t their relative dependences).
The time delay of data
retrieval is influenced also by the data cache (operating system and others).
To eliminate this influence, we exit the VFP application after each test. We observe the time delay only of the first
retrieval.
The CDX file contains
also the index tag: “index on deleted() tag dele of orders”. With this index
tag all the query in this article are full optimized as reported by the
function sys(3054,12). There are no deleted records in the observed tables.
I have made 10
measurements for each retrieval method and I present it in tables to have an
idea of the relationships between them. In my measurement I have used
relatively simple SQL queries, so changing the type of a query, doesn't have significant
impact on the speed of transfer. I shall not study the influence of the number
of fields and its structure on the time delay. I suppose that with the growing
of the number of fields in the result set, the time to fetch the data also
grows.
Using the keyword
DISTINCT in the SQL query, doesn’t improve the data retrieval, so I query
without it.
2.1 Table normalization and the cost of a SQL JOIN
‘If you try to join
two files, each of which contains a few hundred thousand records, you could be
in for some serious waiting' [6]. How to easy this problem?
From the technical
point of view, we can “reduce the normalization” of the two tables: We delete
the field OrderDate from the table OrdNorm and add this field to the table OrdDet.
So, it has all the fields from our original two tables.
Let us concentrate our
attention on the table OrdDet. It has all
the data so it has duplicate records. We can retrieve all the data from this
table without using JOIN.
SELECT wareid, doctype, orderid, shipdate FROM orddet WHERE wareid+ doctype= "14 4" and orderid>170000 INTO CURSOR (lc1) GROUP BY wareid, doctype, orderid, shipdate (Q2)
If we run the query Q2
on the workstation, VFP fetch the big result set of 6,000 records in 14.64
seconds. The difference between the query Q1 and Q2 are the SQL JOIN clause,
which is missing in the query Q2. The cost
of a SQL JOIN (or table normalization) is about 5% (from 15.37 seconds to 14.64).
In certain cases we improve the performances of the VFP duplicating the records
in the table and so eliminating the SQL JOIN in ours SQL statements. Later in
this article we shall see that the cost off table normalization (performance
penalty) has negative correlation with the dimension of the result set and surpasses
100%.
2.2 Store procedure
There are various
methods for data retrieval in VFP, let us mention some:
-
SQL
query;
-
store
procedure;
-
local
view;
-
remote
view with OleDbData provider;
-
cursor
adapter based on local view, remote view, store procedure...;
-
others;
We have tested the
performances of VFP with SQL query in the preceding section. Let us profoundly study
the store procedure, which we can use in various modes.
2.2.1 SQL command in stored procedure
Let us first try an example in which we retrieve
the data with the SQL command in the stored procedure.
PROCEDURE SQLTest1()
SET OPTIMIZE ON
lcCurs=SYS(2015)
SELECT wareid, doctype, orderid, shipdate FROM orddet WHERE wareid+ doctype= "14 4" and orderid>170000 GROUP BY wareid, doctype, orderid, shipdate INTO CURSOR (lcCurs)
RETURN SETRESULTSET(lcCurs)
Listing 1. Store procedure with the SQL
query Q2.
On the workstation we
obtain the same time delay running the store procedure in Listing 1 and the
query Q1 in the command window. We haven't much control on the operation of the
standardized SQL query. So, let us change the store procedure and give it a little
bit more of our personal knowledge as in Listing 2.
2.2.2 Stored procedure
Let us write a stored
procedure with a »classic« seek and do while ... enddo loop. The program in
Listing 2 is self explanatory.
PROCEDURE DOWHILETest(lOrderIdFrom as integer, lOrderIdTo as integer)
SET OPTIMIZE ON
LOCAL lWareId as string, lno as integer, lccur as string, lDocType as string, lc1 as String
lWareId="14 " && we are working with the orders in warehouse with ID 14.
lDocType='4'
lccur=SYS(2015)
*create a cursor to store in the recordset
CREATE CURSOR (lccur)(OrderID N(6), OrderDate D(8), DocType C(1),WareId C(3),ShipDate D(8))
IF NOT USED("Orddet")
SELECT 0
USE Orddet
ELSE
SELECT Orddet
ENDIF
SET ORDER TO WTO
* Find the first record with the order ID grater or equal to lOrderNoFrom
SET EXACT OFF
FOR i=0 TO lOrderIdFrom+100000
IF INDEXSEEK(lWareId+lDocType +STR(lOrderIdFrom+i,6),.t.,"Orddet")
*If not found, seek the next OrderId
INDEXSEEK(lWareId+lDocType +STR(lOrderIdFrom+i,6),.t.,"Orddet")
EXIT
ENDIF
ENDFOR
SELECT Orddet
DO WHILE WareID+DocType==lWareID+lDocType AND orderid<=lOrderIdTo NOT EOF()
lOrderID=OrderID
lOrderDate=OrderDate
lShipDate=ShipDate
DO WHILE WareID+DocType==lWareID+lDocType AND OrderID= lOrderID AND NOT EOF()
SKIP
ENDDO
SELECT (lccur)
INSERT INTO (lccur) (OrderID,OrderDate,DocType,Wareid,ShipDate) VALUES (lOrderID,lOrderDate,lDocType,lWareId,lShipDate)
SELECT orddet
ENDDO
lccur1=SYS(2015)
SELECT * FROM (lccur) INTO CURSOR (lccur1) GROUP BY OrderID,OrderDate, DocType, Wareid,ShipDate
RETURN
SETRESULTSET(lccur1)
Listing 2. Store procedure on the table
OrdDet with a seek, do while .. enddo and a cursor.
Close data
lOrderIdFrom=170000
lOrderIdTO=180500
local t1
t1=seconds()
DOWHILETest(lOrderIdFrom, lOrderIdTO)
?seconds()-t1
brow
Listing 3. The program for testing the
store procedure
The stored procedure
in Listing 2 collects the data from the table OrdDet in the do while loop, put them
in the cursor and return the cursor.
We test the query Q1
against the store procedure in Listing 2 with the program in Listing 3. At the
workstation the retrieval times of the
result set with 100 records are significantly different. The store procedure is at least 273% faster
(0.11 seconds the store procedure and 0.30 seconds the SQL select with a JOIN).
The FULL optimized
query means only that the SQL select is entirely based on the indexes and not
on giving us the minimal retrieval time! In our case, the store procedure is
better according to this criterion (See also [9]).
2.2.3 The method and the normalization influence
On small result set we
obtain the difference in retrieval times of 273%. Is this due to the
normalization or is the result of the used method (stored procedure)? Let us observe the difference in time
between:
1)
retrieving data from a table with duplicate records (the SQL command on the table orddet with duplicate records) (the
Q2 query with 100 records),
2)
against
using JOIN for two normalized tables
(SQL commands with the JOIN keyword (normalized tables ordnorm and orddet) (Q1
for 100 records).
The arithmetic mean
retrieval times for 100 records with the:
-
query
Q2 (duplicated records) is 0,22 seconds;
-
and
Q1 (JOIN) is 0,28 seconds.
With the store
procedure I retrieve the result set of 100 records in 0,11 seconds, 100% (0.22)
slower is the query on the table with duplicated records and at least 173%
(0,30) slower is the query Q1: 100%
derive from the method (store procedure) and 73% is due to table normalization
(JOIN). In certain cases the costs of
normalization are 73% slower retrieval times!!!
The cost of the method used is 100%.
The fans of the
standardized SQL commands can retrieve data 73% faster reducing the table
normalization (using duplicate records in tables). With the store procedure or
similar programs they can navigate also 173% faster, especially in environment
with “thin wire” and work stations with low RAM where they normally download
small result sets.
The differences in retrieval
times for the result set of 100 records on the server (desktop application)
have great variability and we will not study it.
1. The medium size result set of 1,400 records
The tests on the 1,400 records result set shows that the
store procedure (2.14 seconds) is the fastest, the cost of the method (SQL) is 11%
slower retrieval time (2.38 seconds) and the cost of normalization (SQL with
the JOIN) is 8% (2.58 seconds). In total we have a difference of 19%.
2. The large size result set of 6,000 records
|
|
Method |
|||
|
No.of
records |
store
unique |
store
normal |
SQL
duplicated |
SQL
join |
|
6000 |
4,72 |
13,67 |
14,64 |
15,37 |
|
1400 |
0,99 |
2,14 |
2,38 |
2,58 |
|
100 |
0,08 |
0,11 |
0,22 |
0,3 |
Table 1. Retrieval times in seconds on
the workstation
The measurement in Table1
show us that on large result sets the retrieval times differs for 11% (13.67:15.37
seconds) (We shall explain later the column »store unique«).
|
|
Methods |
|||
|
No.of
records |
store
unique |
store
normal |
SQL
duplicated |
SQL
join |
|
6000 |
0,3 |
1,03 |
1,61 |
2,01 |
|
1400 |
0,08 |
0,21 |
0,24 |
0,39 |
Table 2. Retrieval times in seconds on
the server/desktop
Retrieving this result
set directly on the server give us 51% difference (1,03:2,01 seconds, Table 1).
We must consider this difference especially when working on desktop application
or in case we retrieve the data with processes directly on the server computer
(for example asynchronously or with drivers).
2.3 The size of the index file
The SQL query (Q2) is
measured on the table with a »big« 68MB CDX file and on a »small« 15MB files.
Deleting a tag, we can reduce the size of the CDX file for about 3MB.I have
deleted some for the test irrelevant tags, reducing the dimension of CDX file
from 68MB to 24 MB. Reducing the size of the CDX file we reduce the time delay
for about 10%.
We can optimize the time delay also by reducing the size of the CDX
file.
“When adding indexes
to your tables, you must balance the benefit you get in retrieval times against
a performance loss when updating the table. As you add more indexes to your
table, updates and inserts to the table are slower because Visual FoxPro needs
to update each index« (VFP9 Help). To this instruction we can add: Also the data retrieval is slower with
large index file. Too much of them might work against you.
2.4 Unique index
We create the unique
index of the table orddet in the VFP command window:
index on WareId+DocType+str(OrderId,6)+dtoc(ShipDate) tag WTOU unique
The unique index point
only on the first record of the duplicated records set. Deleting the first of
them, VFP don’t move the pointer to the next record in the group. We must
reindex the table, so the index reflects the new state of the table. Normally
we delete the documents in the database only with administrative tools. In similar
situation we must also reindex the table. We have to use unique indexes with
care. Some developers don’t like them.
PROCEDURE DOWHILETestU(lOrderIdFrom as integer, lOrderIdTo as integer)
SET OPTIMIZE ON
LOCAL lWareId as string, lno as integer, lccur as string, lDocType as string, lc1 as String()
lWareId="14 " && we are working with the orders in warehouse with ID 14.
lDocType='4'
lccur=SYS(2015)
CREATE CURSOR (lccur)(OrderID N(6), OrderDate D(8), DocType C(1),WareId C(3),ShipDate D(8))
IF NOT USED("Orddet")
SELECT 0
USE Orddet
ELSE
SELECT Orddet
ENDIF
SET ORDER TO WTO
SET EXACT OFF
FOR i=0 TO lOrderIdFrom+100000
IF INDEXSEEK(lWareId+lDocType +STR(lOrderIdFrom+i,6),.t.,"Orddet")
INDEXSEEK(lWareId+lDocType +STR(lOrderIdFrom+i,6),.t.,"Orddet")
EXIT
ENDIF
ENDFOR
SELECT Orddet
DO WHILE WareID+DocType==lWareID+lDocType AND orderid<=lOrderIdTo NOT EOF()
lOrderID=OrderID
lOrderDate=OrderDate
lShipDate=ShipDate
SKIP
SELECT (lccur)
INSERT INTO (lccur) (OrderID,OrderDate,DocType,Wareid,ShipDate) VALUES (lOrderID,lOrderDate,lDocType,lWareId,lShipDate)
SELECT orddet
ENDDO
lccur1=SYS(2015)
SELECT * FROM (lccur) INTO CURSOR (lccur1) GROUP BY OrderID,OrderDate, DocType,Wareid,ShipDate
RETURN SETRESULTSET(lccur1)
Listing 4. The stored procedure with
unique index WTOU and without the second dowhile loop.
We modify the
procedure in Listing 2, we change the index from WTO to WTOU and remove the
second DoWhile loop. The program is in Listing 4.
Using the stored
procedure with the unique index, we reduce the retrieval times for the result
set of 6,000 records from 13,67 to 4,72 seconds (Table 1). The cost of not using the unique index is about 290% (also for large
result sets).
2.5 The penalty of normalization
Let us study the
question: what is the penalty we pay, if we normalize a table
a)
using
only the standardized SQL queries,
b)
without
using the unique indexes,
c)
using
the unique index?
|
|
Methods |
Differences between methods |
||||
|
No.of
records |
store
unique |
store
|
SQL
duplicated |
SQL
join |
SQL
join -store |
SQL
join - SQL duplicated |
|
100 |
100 |
138 |
275 |
375 |
41 |
32 |
|
1400 |
88 |
191 |
213 |
230 |
238 |
100 |
|
6000 |
98 |
285 |
305 |
320 |
39 |
18 |
Table 3. Method and normalization productivity
in % for the retrieval of 1000 records on the workstation
I shall modify the
data in Table 1.Think the size of the result set to be a method. We have 12
theoretical methods (3 method for retrieving 4 different result set) (Table 4).
In Table 3 I calculated the penalty (productivity) in % of the 12 methods with
the retrieval time of 1,000 records (retrieval times/1,000 records). (The base
cell in Table 3 is the cell with value 100). We obtain 12 productivities in % for
the 12 methods.
The most productive
(lowest penalty) are the methods based on medium size result set (the second
row in Table 3).
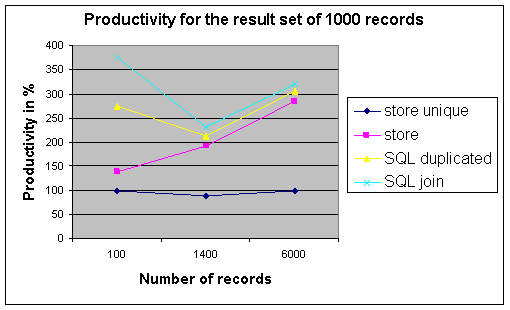
Figure 1. Method and normalization productivity
in % for the result set of 1000 records on the workstation
a)
Using
only the standardized SQL queries we pay the penalty in range from 18 to 100%
(the last column in Table 3).
b)
Using
the optimal query method we pay a normalization penalty in range from 39 to
238% (the penultimate column in Table 3).
c)
If
we use unique indexes the normalization
penalty is in range from 130 to 275%. Retrieving the data without unique
indexes, we reduce the productivity for at least 130% (see Figure 1).
The between methods
variability depends on the fetched result set (Figure 1). On small result set the
differences in productivity arrive to 275%.
The methods based on
unique indexes are linear, have linear dependence from the number of records in
the result set (the line store unique in Figure 1). If we retrieve 100 records
in 0.08 seconds, we can predict to fetch 1,000 records in 0,8 seconds.
3 The tests results
The most important
results of our tests are presented in Table 1 and Table 3.
The full optimized SQL command fetches the record set of 100 records
from the server about 100% slower than the stored procedure. Full rushmore optimization reported by the function sys(3054,12)
means that the SQL query data select is totally based on indexes and not on
being the fastest data selection the VFP9 can produce. It’s programmer’s job to
create optimal retrieval methods.
In network environment
the theory of table normalization
must be revisited (see also [9]). From the point of view of minimal retrieval
time it’s appropriate to built database architecture with only minimal table normalization. We can
optimize the data retrieval times from the no-normalized tables also with
writing store procedure and other fast retrieval, non SQL based procedures and
using unique indexes. Normalizing the tables we can reduce the
productivity for three times.
The size of the result set has great influence on the difference
between the productivity of data retrieval methods.
The methods that have similar productivity on large result sets can be
significantly different (that exceed also 100%) on smaller result sets.
Programmers have to choose appropriate retrieval methods according to the size
of the result set.
Every index tag added to the structural CDX of a dbf table of size 350MB increases the CDX size for about 3MB. Eliminating the “unnecessary” tag we can significantly reduce the CDX size and improve the VFP performance.
4 Future research
We have observed only
the first retrieval of the data after opening the application. What is the
performance of the observed retrieval methods on the second and next try? It is
interesting also the comparison of the VFP retrieve performance when concurrent
users access the database. How decrease the server response time when multiple
users retrieve the data in small and/or large chunk? The newer technologies for
distributed computations (for example WCF) are easy to use so we can find
solutions also outside VFP, for example in asynchronous data retrieval using
the WCF service and (or) VFP OLE server. The server retrieval time for 6,000 records
is only 0,65 seconds. If the download and other data transformation is, for
example 1,35 seconds, we can have large result set at the station in 2 seconds, without application blocking.
References:
[1]. Robert C. Bradley: Visual FoxPro - Client/Server
[2]. Eldor Gemst: Remote Views SQL Pass-Through
[3]. Ted Roche: Intermediate Client-Server Techniques
[4]. Marco Antonio Mazzarino: Asynchronous Use of VFP
[5] L. Pinter: A
FoxPro Server
[6] Josip
Zohil: Periodical Asynchronous Requests in VFP Forms
[7] Mike Hillyer: An Introduction to Database Normalization
[8] Christof Wollenhaupt: How FoxPro works internally
[9]. P.Helland: Scaling Secret #2: Denormalizing Your Way to Speed and Profit